Wow, it’s been a while since I’ve dropped by here. But it’s all worth it as I want to share my experience in replacing my Ubiquiti EdgeRouter Lite 3 flash drive. It has been a rather long journey, so I thought I’d share my experience.
I will not enter into all the technical details but here is a rough list of what I used. This was done on a laptop running with Ubuntu Bionic.
- A USB to RJ-45 console cable
- minicom with the suggested setup from the official doc (115200-8bits-No parity-1 stop)
- tftpd-hpa : the tftp server
Diagnostic
Coming back from my summer vacation, I found my ERL 3 no longer working. After trying the official documentation and seeing that no IP address was set on ports ETH0 / EHT1 as outlined in the doc, I elected to check the console port.
My first try gave me this :
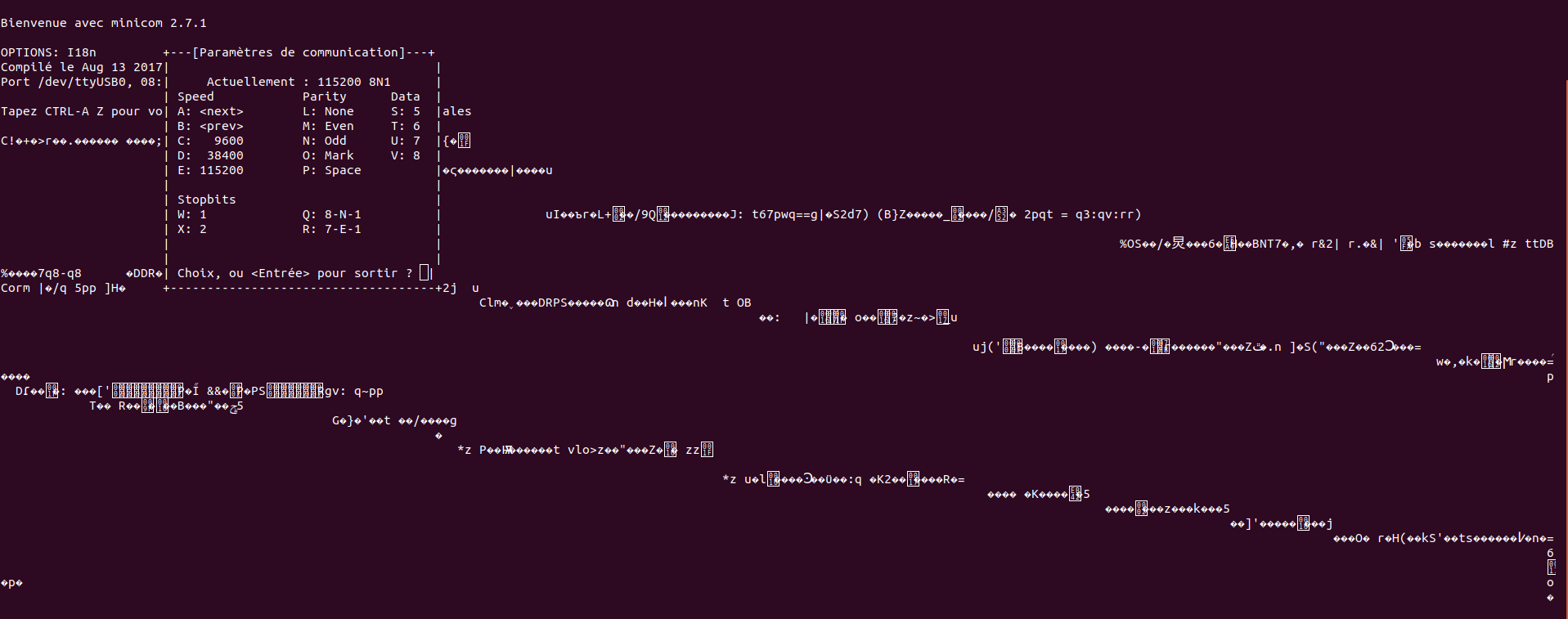
For some reason, only garbage came out of the console port. An hour of googling lead me to believe that the USB console cable was the culprit. A colleague lent me another cable and I got this which was already much better :
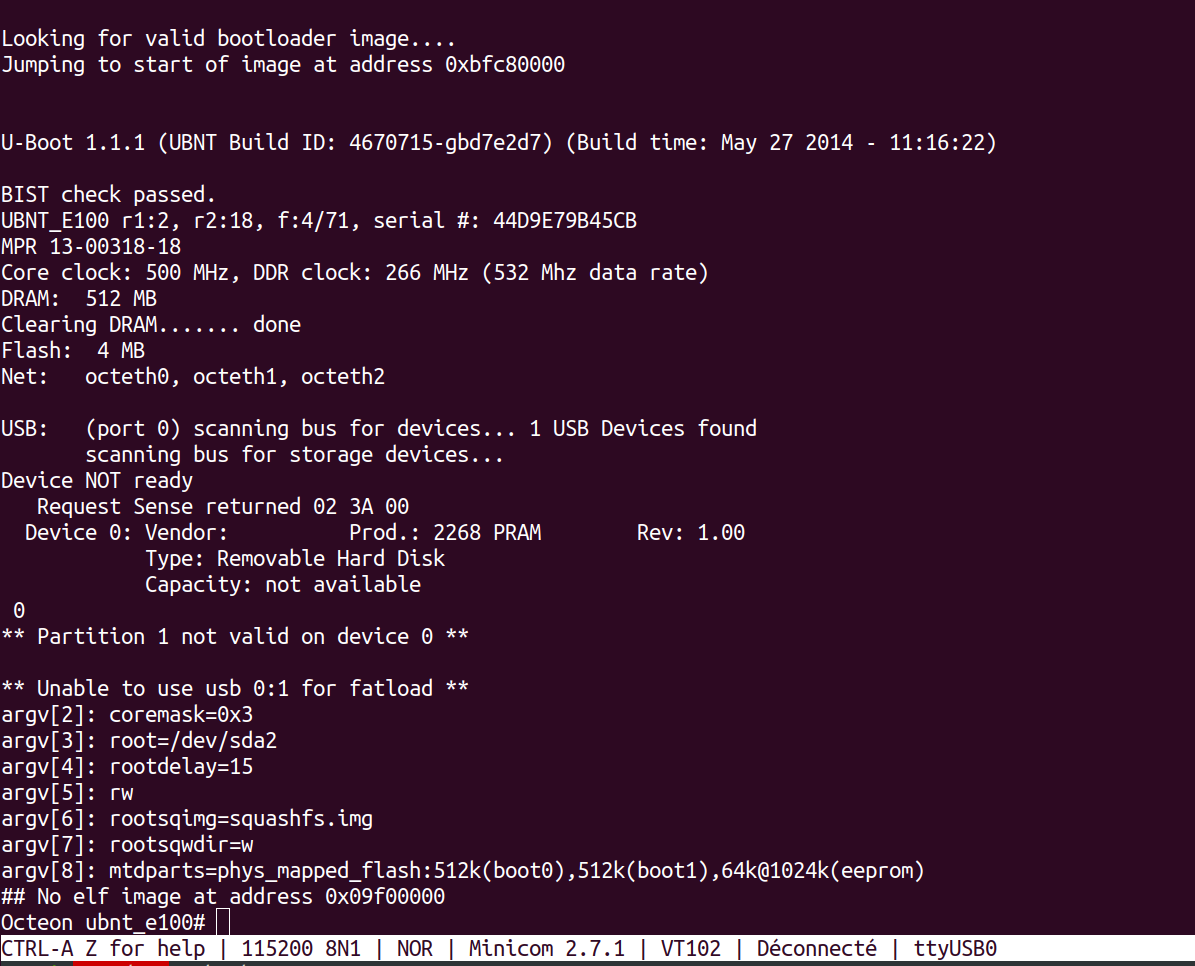
At this point, I should have been a bit more attentive on the message displayed. I got distracted by the fact that some USB Device was seen by the firmware as seen in :
USB: (port 0) No USB devices found.0
The next two lines clearly indicated that the firmware was not able to access the partitions on the flash drive :
** Partition 1 not valid on device 0 **
** Unable to use usb 0:1 for fatload **
Setting up the TFTP server
This is not the topic of this article, but in short, on Ubuntu you need to install the tftpd-hpa package and you are all set. The image files to be served by TFTP are to be copied in /var/lib/tftpboot.
Identifying the real problem
After some more googling, I found this very good article that, while not being specific on the flash drive replacement, explains very well how to use a TFTP server to load : Recovering an unresponsive Ubiquiti EdgeRouter Lite router. My own article uses portion of this post so I am very thankful to Darren Scott for writing this.
For me, the most useful instructions on this article is how to set the Ubiquiti firmware to be able to fetch a file using tftp. Remember that, so far, I have not been able to reach my router on the network. Even setting up my laptop nic with a 192.168.1.10 ip address did not let me reach the supposed 192.168.1.20 ip address configured on the ETH0 port of the router. I supposed that this is setup by the Ubiquiti firmware stored on the flash drive. Using the following commands, I was able to trigger a TFTP download from my laptop :
# set ipaddr 192.168.1.20# set netmask 255.255.255.0# set serverip 192.168.1.10# set bootfile ER-e100.recovery.v2.0.6.5208553.190708.0607.16de5fdde.img.signed# tftpboot
I tried his method using the ERLite-3 / ERPoE-5 (e100) image proposed in the official documentation but got the following :
Octeon ubnt_e100# set ipaddr 192.168.1.20Octeon ubnt_e100# set netmask 255.255.255.0Octeon ubnt_e100# set serverip 192.168.1.10Octeon ubnt_e100# set bootfile ER-e100.recovery.v2.0.6.5208553.190708.0607.16de5fdde.img.signedOcteon ubnt_e100# tftpbootInterface 0 has 3 ports (RGMII)Using octeth0 deviceTFTP from server 192.168.1.10; our IP address is 192.168.1.20Filename 'ER-e100.recovery.v2.0.6.5208553.190708.0607.16de5fdde.img.signed'.Load address: 0x9f00000Loading: octeth0: Up 1000 Mbps Full duplex (port 0)################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################################89 MB received##########################################################################################################################################doneBytes transferred = 113549500 (6c4a0bc hex), 7316 Kbytes/secWARNING: Data loaded outside of the reserved load area, memory corruption may occur.WARNING: Please refer to the bootloader memory map documentation for more information.
The indication WARNING: Data loaded outside of the reserved load area, memory corruption may occur. Made me think that the image was too big to fit in the boot memory section. So this was not the solution.
Finding the EdgeMax Rescue Kit
Darren Scott’s blog post refers to another Ubiquiti Community post called EdgeMax rescue kit (EMRK). This is the kit used to reset the router in Darren’s article. Unfortunately, the links given to download EMRK are all dead. After some research, I was able to locate this EMRK download link : https://downloads.vyos.io/?dir=tools/emrk/0.9c. Let’s home that is remains available.
Replacing the flash drive



Reinstalling Ubiquiti firmware
Looking for valid bootloader image....Jumping to start of image at address 0xbfc80000U-Boot 1.1.1 (UBNT Build ID: 4670715-gbd7e2d7) (Build time: May 27 2014 - 11:16:22)BIST check passed.UBNT_E100 r1:2, r2:18, f:4/71, serial #: 44D9E79B45CB MPR 13-00318-18 Core clock: 500 MHz, DDR clock: 266 MHz (532 Mhz data rate)DRAM: 512 MB Clearing DRAM....... done Flash: 4 MB Net: octeth0, octeth1, octeth2 USB: (port 0) No USB devices found. 0 ** Partition 1 not valid on device 0 ** ** Unable to use usb 0:1 for fatload **argv[2]: coremask=0x3 argv[3]: root=/dev/sda2 argv[4]: rootdelay=15 argv[5]: rw argv[6]: rootsqimg=squashfs.imgargv[7]: rootsqwdir=w argv[8]: mtdparts=phys_mapped_flash:512k(boot0),512k(boot1),64k@1024k(eeprom)## No elf image at address 0x09f00000 Octeon ubnt_e100# set ipaddr 192.168.1.20 Octeon ubnt_e100# set netmask 255.255.255.0 Octeon ubnt_e100# set serverip 192.168.1.10 Octeon ubnt_e100# set bootfile emrk-0.9c.binOcteon ubnt_e100# tftpbootInterface 0 has 3 ports (RGMII)Using octeth0 device [30/71]ur IP address is 192.168.1.20Filename 'emrk-0.9c.bin'.Load address: 0x9f00000Loading: octeth0: Up 1000 Mbps Full duplex (port 0)##############################################################################################################doneBytes transferred = 15665511 (ef0967 hex), 7369 Kbytes/secOcteon ubnt_e100# bootoctlinux $loadaddrELF file is 64 bitAllocating memory for ELF segment: addr: 0xffffffff81100000 (adjusted to: 0x1100000), size 0xe83940Allocated memory for ELF segment: addr: 0xffffffff81100000, size 0xe83940Processing PHDR 0Loading e23d80 bytes at ffffffff81100000Clearing 5fbc0 bytes at ffffffff81f23d80## Loading Linux kernel with entry point: 0xffffffff81105ca0 ...Bootloader: Done loading app on coremask: 0x1Linux version 2.6.32.13-wau (dmbaturin@v-dev) (gcc version 4.3.3 (Cavium Networks Version: 2_0_0 build 95) ) #81 SMP Tue Jul 23 13:51:58 PDT 2013CVMSEG size: 2 cache lines (256 bytes)Cavium Networks SDK-2.0bootconsole [early0] enabledCPU revision is: 000d0601 (Cavium Octeon+)Checking for the multiply/shift bug... no.Checking for the daddiu bug... no.Determined physical RAM map:...Loading EMRK 0.9a [107/666]Mounting filesystems Bringing up eth0 Checking boot partition Boot partition is missing or has wrong filesystem type! Checking root partition Root partition is missing or has wrong filesystem type!********************************************** Welcome to EdgeMax Rescue Kit! This tool is distributed under the terms of GNU General Public License and other licenses Brought to you by SO3 Group WARNING: This tool is not developed, officially supported or endorsed by Ubiquiti Networks!
Using it may lead to destroying your routerconfiguration or operating system
Ubiquiti Networks support will not help youwith using it or fixing consequences ofusing it.
This tool itself is distributed without anywarranty and authors are not liable forany damage it may cause
By using this tool you agree you are doingit at your own risk and understand whatyou are doing
*********************************************
Enter 'Yes' to proceed, 'No' to rebootyes or no: yes
Do you want to configure network via DHCP?yes or no: no
Do you want to configure network statically?yes or no: yesEnter IPv4 address in CIDR format (e.g. 192.0.2.10/24): 192.168.1.20/24Enter IPv4 gateway address: 192.168.1.1Enter DNS server address: 192.168.1.1
EMRK provides some scripts for automatedrecovery procedures:
emrk-factory-reset -- reset config to factory defaultemrk-remove-user-data -- remove all the user data includingconfig and everythingemrk-reinstall -- reinstall EdgeOS from scratch(wipes any user data too)
Enter 'reboot' to reboot your router
BusyBox v1.17.1 (Debian 1:1.17.1-8) built-in shell (ash)Enter 'help' for a list of built-in commands.
ob control turned offEMRK>emrk-reinstallWARNING: This script will reinstall EdgeOS from scratchIf you have any usable data on your router storage,it will be irrecoverably destroyed!Do you want to continue?yes or no: yes
Re-creating partition table
Creating boot partition
Formatting boot partition
mkfs.vfat 3.0.9 (31 Jan 2010)
Creating root partition
Formatting root partition
Mounting boot parition
Mounting root partition
kjournald starting. Commit interval 5 seconds
EXT3 FS on sda2, internal journal
EXT3-fs: mounted filesystem with writeback data mode. Enter EdgeOS image url: tftp://192.168.1.10/ER-e100.v1.10.11.5274249.tar
% Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left Speed
Unpacking EdgeOS release image Verifying EdgeOS kernel Copying EdgeOS kernel to boot partition Verifying EdgeOS system image Copying EdgeOS system image to root partition Copying version file to the root partitionCreating EdgeOS writable data directoryCleaning upInstallation finishedPlease reboot your router
Once this is completed you can reboot your Ubiquiti EdgeRouter Lite 3. After the boot sequence you should see the well known :
Welcome to EdgeOS ubnt ttyS0
By logging in, accessing, or using the Ubiquiti product, you
acknowledge that you have read and understood the Ubiquiti
License Agreement (available in the Web UI at, by default,
http://192.168.1.1) and agree to be bound by its terms.
ubnt login:
Voilà !